
After your application grows, SQL queries might become slow. Let's check the halilcosdu/laravel-slower package, which can help to improve query performance, using AI.
Imagine you have a dashboard and a query to get some stats.
$categoryStats = DB::table('categories') ->select([ 'categories.name', 'categories.slug', DB::raw('COUNT(DISTINCT posts.id) as post_count'), DB::raw('COALESCE(AVG(posts.view_count), 0) as avg_views'), DB::raw('(SELECT COUNT(*) FROM comments JOIN posts p2 ON comments.post_id = p2.id WHERE p2.category_id = categories.id) as total_comments') ]) ->leftJoin('posts', 'categories.id', '=', 'posts.category_id') ->groupBy('categories.id', 'categories.name', 'categories.slug') ->orderByRaw('post_count DESC') ->get();In the dashboard, the result is shown similar to the image:
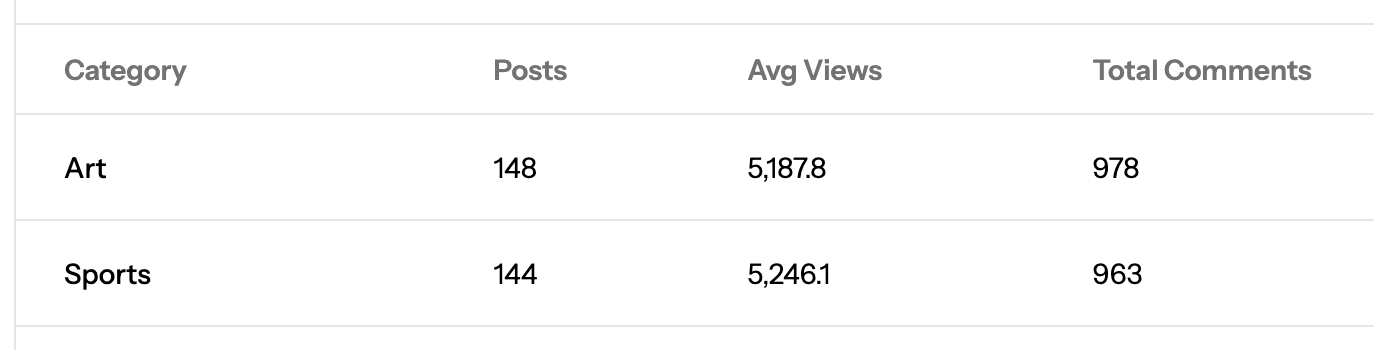
The query with no improvements takes about 13 seconds to run, which is very long.
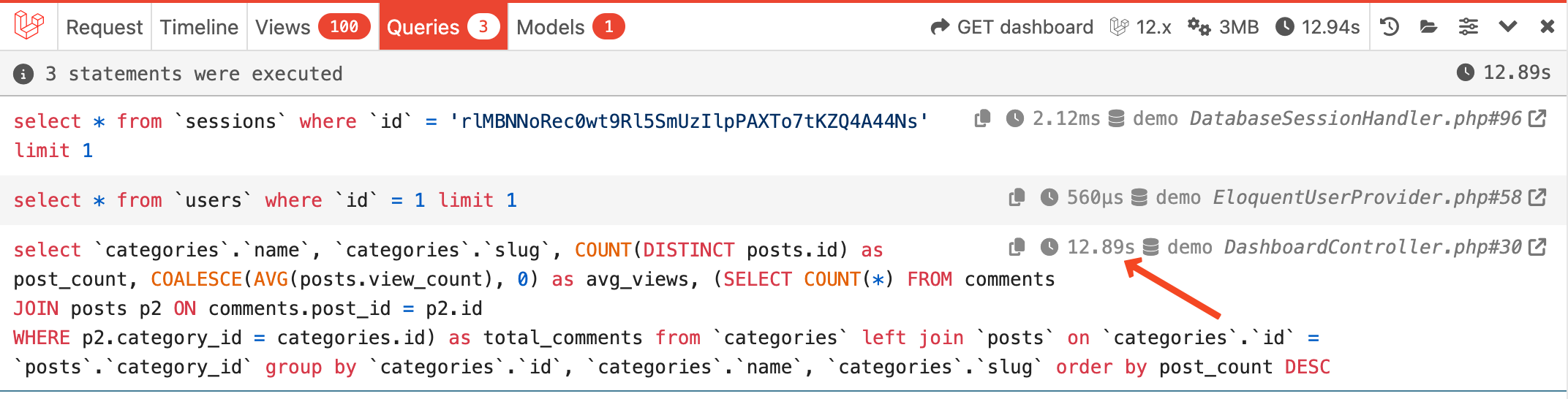
The package logs all slow queries into the database:

The default value is 10000ms, which is 10s. If the query exceeds this time, then it is logged. The threshold time is set in the package's config/slower.php file or as an SLOWER_THRESHOLD environment variable.
When there are logged queries, the package provides an Artisan command slower:analyze to analyze all the queries that have is_analyzed as false in the database.
When I tried to analyze this SQL query, I got an Illuminate\Database\QueryException Exception. Setting SLOWER_AI_RECOMMENDATION_USE_EXPLAIN to false in the .env made the analysis work.
Before running the analyze command, you have to set your OpenAI API key in the
OPENAI_API_KEYin the .env file.
After running the php artisan slower:analyze command in the terminal, the result is:
php artisan slower:analyzeHigh-level findings- The query is dominated by two things:...------------------------------------All doneYou can find the result in the slow_logs table under the recommendation column.
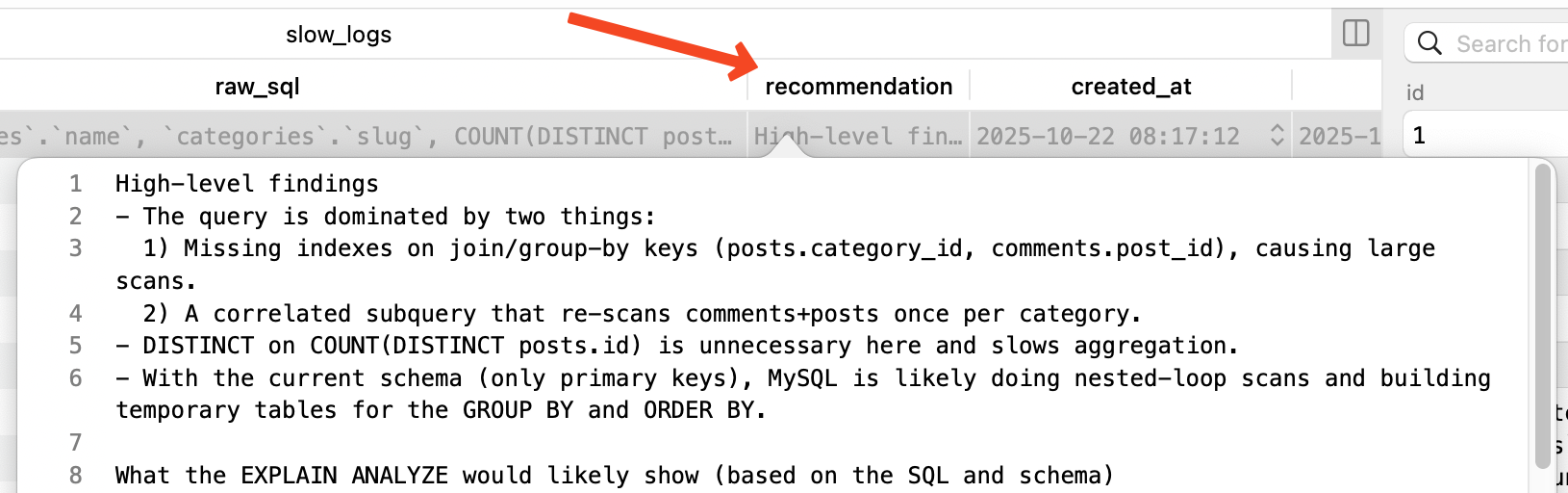
The recommendation that AI gave in this case:
High-level findings- The query is dominated by two things: 1) Missing indexes on join/group-by keys (posts.category_id, comments.post_id), causing large scans. 2) A correlated subquery that re-scans comments+posts once per category.- DISTINCT on COUNT(DISTINCT posts.id) is unnecessary here and slows aggregation.- With the current schema (only primary keys), MySQL is likely doing nested-loop scans and building temporary tables for the GROUP BY and ORDER BY. What the EXPLAIN ANALYZE would likely show (based on the SQL and schema)- categories as the driving table.- For each category, a left join to posts without an index on posts.category_id → repeated full scans or poor range scans.- A “Dependent subquery” for total_comments executing per-category, joining comments to posts without supporting indexes (full scans or large temporary work each time).- “Using temporary; Using filesort” on the GROUP BY / ORDER BY.These patterns are consistent with the 13+ second runtime. Indexes to add (low risk, high impact)1) posts(category_id, view_count) - Lets MySQL aggregate per category using an index-only scan for COUNT(*) and AVG(view_count). - If you don’t want to include view_count, add posts(category_id) at minimum. 2) comments(post_id) - Supports the join comments.post_id = posts.id efficiently. Optional/conditional indexes- If you commonly filter by published posts, consider posts(category_id, is_published, view_count) to support both filtering and covering aggregation.- If you will continue to use the original query shape (LEFT JOIN posts … GROUP BY categories.*), posts(category_id) alone still dramatically reduces join cost. Query rewrite (remove correlated subquery and DISTINCT, push aggregation into derived tables)Replace your query with this form: SELECT c.name, c.slug, COALESCE(p.post_count, 0) AS post_count, COALESCE(p.avg_views, 0) AS avg_views, COALESCE(cm.total_comments, 0) AS total_commentsFROM categories cLEFT JOIN ( SELECT category_id, COUNT(*) AS post_count, AVG(view_count) AS avg_views FROM posts GROUP BY category_id) p ON p.category_id = c.idLEFT JOIN ( SELECT p.category_id, COUNT(*) AS total_comments FROM posts p JOIN comments cm ON cm.post_id = p.id GROUP BY p.category_id) cm ON cm.category_id = c.idORDER BY post_count DESC; Why this is faster- COUNT(DISTINCT posts.id) → COUNT(*) inside the posts-only subquery; DISTINCT is unnecessary because posts.id is unique and there’s no further join duplication at that stage.- The posts subquery can be satisfied via the covering index (category_id, view_count) with “Using index” for GROUP BY, avoiding table lookups.- The comments subquery aggregates once for the whole dataset (not per category row) and joins via comments(post_id) + posts PK; MySQL groups by p.category_id just once.- The outer SELECT only joins two small aggregated result sets back to categories. If you must keep your current single SELECT shape- Still remove DISTINCT: change COUNT(DISTINCT posts.id) to COUNT(posts.id).- Rewrite the correlated subquery into a LEFT JOIN on a pre-aggregated comments-per-category subquery: SELECT categories.name, categories.slug, COUNT(posts.id) AS post_count, COALESCE(AVG(posts.view_count), 0) AS avg_views, COALESCE(cm.total_comments, 0) AS total_commentsFROM categoriesLEFT JOIN posts ON posts.category_id = categories.idLEFT JOIN ( SELECT p.category_id, COUNT(*) AS total_comments FROM comments c JOIN posts p ON p.id = c.post_id GROUP BY p.category_id) cm ON cm.category_id = categories.idGROUP BY categories.id, categories.name, categories.slugORDER BY post_count DESC; Operational tips- Add indexes online if possible: ALTER TABLE posts ADD INDEX idx_posts_category_view (category_id, view_count); ALTER TABLE comments ADD INDEX idx_comments_post (post_id); - Update optimizer statistics after creating indexes: ANALYZE TABLE posts, comments; - Re-run EXPLAIN ANALYZE. You want to see: - No “Dependent subquery”. - The posts aggregation using “Using index” (covering) and “Using index for group-by”. - Joins using ref/eq_ref on the new indexes, not full scans. - If you still see “Using temporary; Using filesort” in the outer ORDER BY (on an aggregate), that is normal and usually acceptable; the heavy lifting should now be in the inner aggregates. Further scaling options (if needed)- Denormalize comment counts by category (and optionally post counts, avg views) into a materialized summary table (category_stats) updated by triggers or asynchronous jobs. Then your query becomes a trivial join to a small summary table, typically sub-millisecond.- Ensure innodb_buffer_pool_size is large enough to hold your hot indexes (especially the new posts(category_id, view_count) and comments(post_id)).- If the comments table is very large, consider pre-aggregating comments per post first (comments_agg with post_id, cnt) and then joining to posts to aggregate per category in a scheduled job. Expected impact- With the two indexes and the rewrite eliminating the dependent subquery and DISTINCT, this pattern typically drops from multi-seconds to tens of milliseconds, depending on table sizes.One of the recommendations is to add indexes.
php artisan make:migration "add index to posts and comments tables"database/migrations/xxx_add_index_to_posts_and_comments_tables.php:
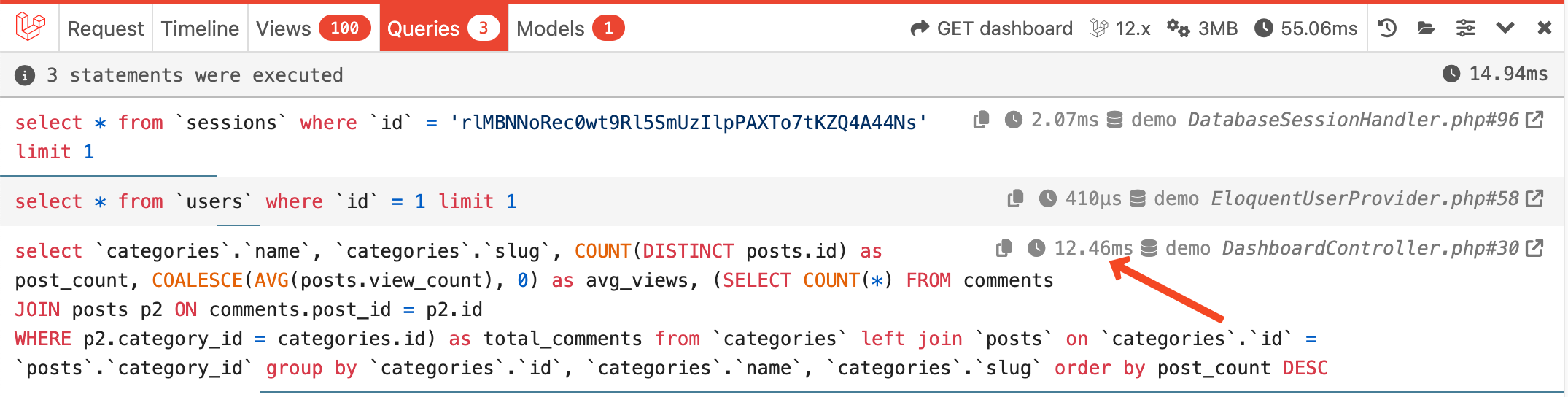
public function up(): void{ Schema::table('posts', function (Blueprint $table) { $table->index('category_id'); $table->index(['category_id', 'view_count']); }); Schema::table('comments', function (Blueprint $table) { $table->index('post_id'); });}After adding these indexes, the query now runs in about 13ms. That's more than 1000 times faster!
What do you think about this package? Would it be useful in your projects?
You can find 200+ more useful Laravel packages in this list on our website.
No comments yet…