
In this course, we started with a few practical examples but can't move on without stopping for some theory. I promise it will be short.
One of the fundamental theories of databases is database normalization. There are different normal forms that your database needs to comply with. It helps prevent data from being duplicated and allows for writing more performant queries.
In theory, the higher the normal form of your database, the better the performance. Not always. It's on a case-by-case basis. But it would help if you strived for at least a third normal form in most cases.
So, in this lesson, I will describe the first/second/third normal forms, what they mean, and what are the more practical examples.
First Normal Form
Look at the example: this database table does not comply with the first normal form because the field tags is comma-separated.

The first normal form says that every value in the table should be so-called atomic, which means it does not contain multiple values in one column.
You would probably agree that to query that table from comma-separated fields would be complicated and affect performance.
We should separate those values. One way of doing that would be to separate those columns. Instead of one column of tags, comma-separated, there could be tag1, tag2, and tag3.

Technically, now it complies with the first normal form. But still, it's not convenient to query. Also, you need to check how many tags there are. So, there should be nullable values.
And it takes a lot of work to add more fields. If you need a fourth or fifth tag, you need to change the database structure.
A better way is to introduce a many-to-many relationship from posts to tags. The most effective result in terms of database structure is to have posts only with text fields.

Then, you have tags in a separate DB table.
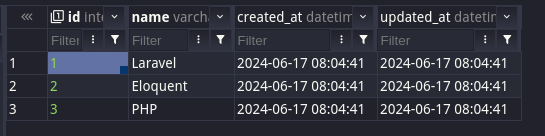
Then, you have a pivot table, post_tag, containing the relationship of which tag belongs to which post.
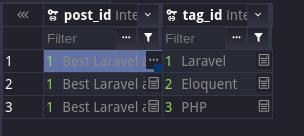
So, this is the first normal form: a single value in each column.
Second Normal Form
The second normal form is kind of a "no-brainer" to understand, and you probably all use it by default. It tries to solve the problem of duplicating data and too much data in the same DB table.
Look at the table of orders. Do you see the problem here?

For every order, we save the customer's name, email, and address. We also have everything related to the order itself, including the product, quantity, and total price.
If the same customer orders several times, we have three duplicate lines in the orders table with the same John Smith, [email protected], and the same address. Wouldn't it be better to extract that in a separate customers table and leave only the order data in the orders table?
That's precisely what the second normal form is about: extracting duplicate data into separate tables.
I have extracted customer data into their own customers table, and then the orders contain only the order data with a foreign key to the customer.


Then, the orders table is much smaller, and if you need the customer data, you can load that with the customer relationship. You can also make faster reports of total order prices or quantities without touching the customers.
Third Normalization Form
The third normal form is similar to the second normal form. I was struggling to come up with an example and found one on Stack Overflow.
|-----Primary Key----| uh oh | VCourseID | SemesterID | #Places | Course Name |------------------------------------------------|IT101 | 2009-1 | 100 | Programming |IT101 | 2009-2 | 100 | Programming |IT102 | 2009-1 | 200 | Databases |IT102 | 2010-1 | 150 | Databases |IT103 | 2009-2 | 120 | Web Design |The second normal form is violated when there is duplicate data. If the course name is repeated, you need to put it in a separate table. We've discussed that.
The third normal form is a subset of a second normal form violation where you have repeating data with their IDs. So, multiple columns. You already have those IDs, but they are not separated into a separate table.
|-----Primary Key----| uh oh | VCourse | Semester | #Places | TeacherID | TeacherName |---------------------------------------------------------------|IT101 | 2009-1 | 100 | 332 | Mr Jones |IT101 | 2009-2 | 100 | 332 | Mr Jones |IT102 | 2009-1 | 200 | 495 | Mr Bentley |IT102 | 2010-1 | 150 | 332 | Mr Jones |IT103 | 2009-2 | 120 | 242 | Mrs Smith |I don't remember seeing anyone do this in practice, but the result is basically the same. You extract into a separate table, and then your database complies with the third normal form.
Primary Key | TeacherID | TeacherName | ---------------------------| 332 | Mr Jones | 495 | Mr Bentley | 242 | Mrs Smith |There are many more normal forms, such as fourth and fifth, and then form numbers with some letters. Satisfying those is not crucially important.
It may be the goal for you, depending on what your queries are from the data. But satisfying the first, second, and third normal forms is almost always a must-have scenario.
Avoid duplicating data. Separate things in separate tables if they need to be separated. This will improve your database performance.
No comments yet…