
SoftDeletes is an Eloquent function that allows you to have the deleted_at column, which is easy to integrate into Filament. Let me show you how.
First, make sure your table has a deleted_at column. To add that column, call the softDeletes() method in your migrations.
Schema::create('tasks', function (Blueprint $table) { // ... $table->softDeletes();});And add the SoftDeletes Trait to your Model.
use Illuminate\Database\Eloquent\SoftDeletes; class Task extends Model{ use SoftDeletes; // ...Fastest way to add soft-deletes
When creating a new resource, you can use the --soft-deletes flag to interact with deleted records, and you're good to go. Filament will set up everything for you automatically.
php artisan make:filament-resource Task --soft-deletesAdding soft deletes to existing resources
You may add a soft-deletes feature to your existing project as well.
Table filtering
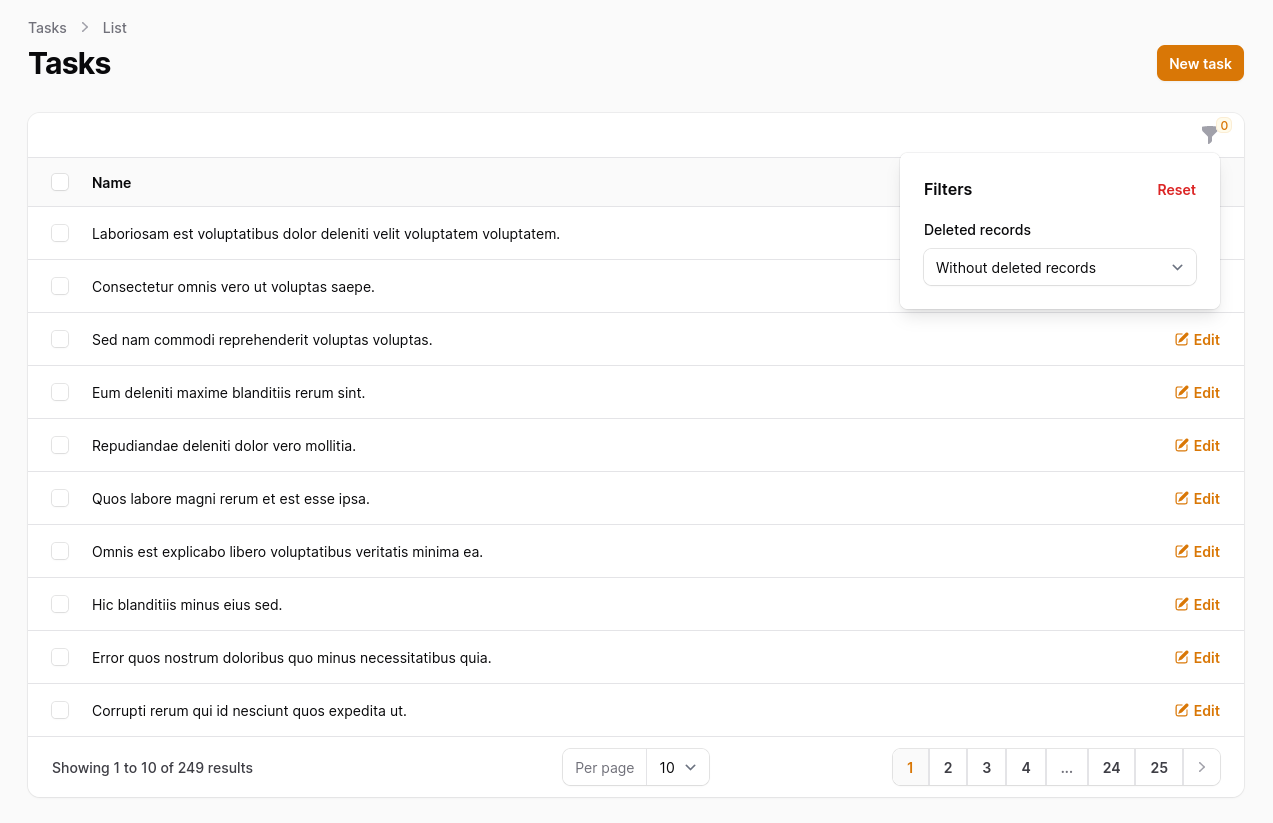
To view a table with/without/only trashed records, overwrite the getEloquentQuery method by adding SoftDeletingScope to the table query.
Then, add TrashedFilter to the table filters.
app/Filament/Resources/TaskResource.php
use Illuminate\Database\Eloquent\SoftDeletingScope; // ... public static function table(Table $table): Table{ return $table ->columns([ Tables\Columns\TextColumn::make('name'), ]) ->filters([ Tables\Filters\TrashedFilter::make(), ]) ->actions([ Tables\Actions\EditAction::make(), ]) ->bulkActions([ Tables\Actions\BulkActionGroup::make([ Tables\Actions\DeleteBulkAction::make(), ]), ]);} public static function getEloquentQuery(): Builder{ return parent::getEloquentQuery() ->withoutGlobalScopes([ SoftDeletingScope::class, ]);}Add ForceDelete, Delete, and Restore buttons to the table

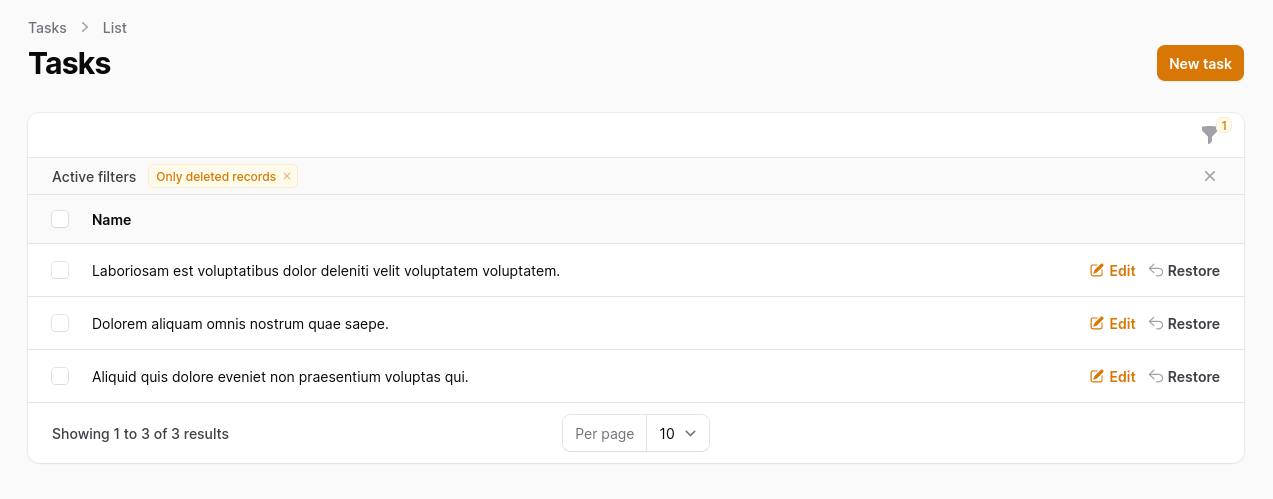
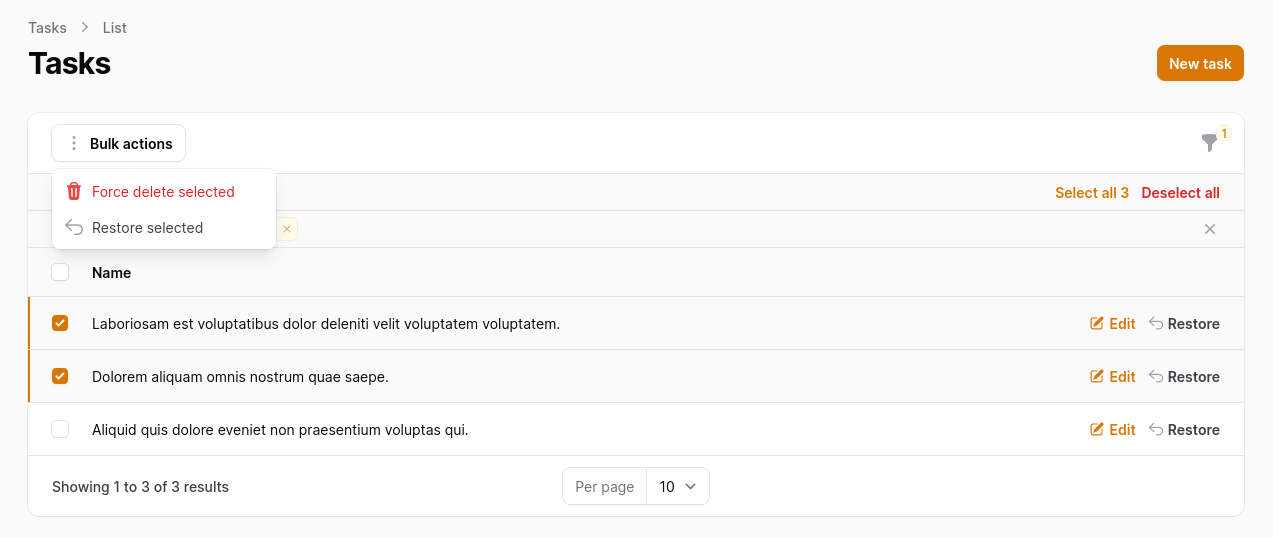
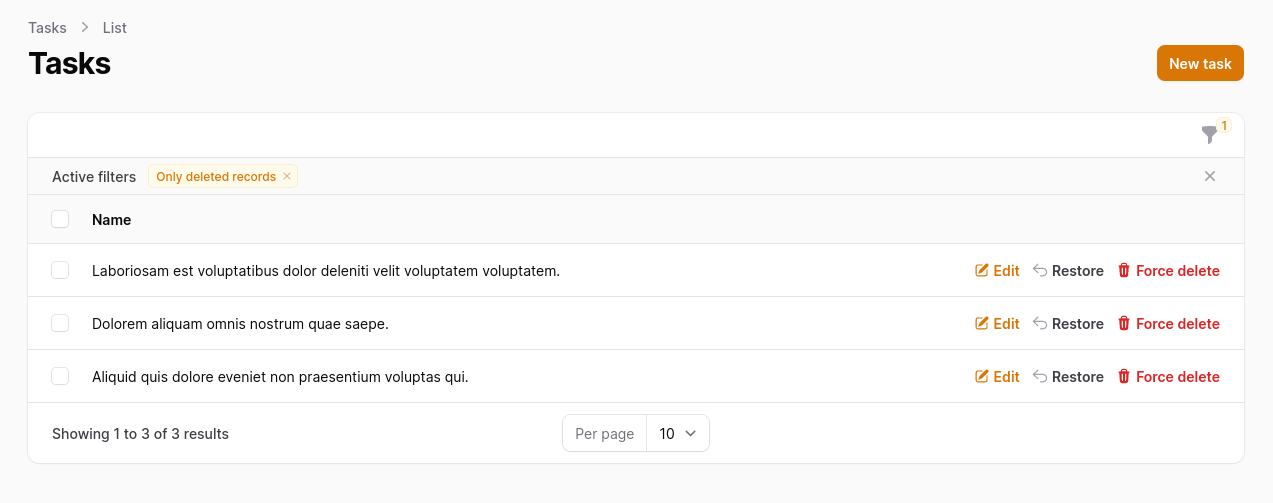
Optionally, you can add more actions to your table to be able to delete, restore, and delete forever those records.
app/Filament/Resources/TaskResource.php
public static function table(Table $table): Table{ return $table ->columns([ Tables\Columns\TextColumn::make('name'), ]) ->filters([ Tables\Filters\TrashedFilter::make(), ]) ->actions([ Tables\Actions\EditAction::make(), Tables\Actions\DeleteAction::make(), Tables\Actions\RestoreAction::make(), ]) ->bulkActions([ Tables\Actions\BulkActionGroup::make([ Tables\Actions\DeleteBulkAction::make(), Tables\Actions\ForceDeleteBulkAction::make(), Tables\Actions\RestoreBulkAction::make(), ]), ]);}Edit page buttons
When editing a trashed record, there's an option to add, force delete, or restore buttons.
app/Filament/Resources/TaskResource/Pages/EditTask.php
class EditTask extends EditRecord{ protected static string $resource = TaskResource::class; protected function getHeaderActions(): array { return [ Actions\DeleteAction::make(), Actions\ForceDeleteAction::make(), Actions\RestoreAction::make(), ]; }}If you want more Filament examples, you can find more real-life projects on our FilamentExamples.com.
A couple of points:
You will almost certainly need an index on
deleted_atbecause normal non-trash eloquent queries will add aWHERE deleted_at IS NULLclause. You should probably combine this with whatever other columns you need to index on into a single index withdeleted_atas the first column (so that only part of the index needs to be read).You need to be aware of an index "gotcha" in some (but not all) SQL database managers which is caused by the SQL definition deciding (in a fit of idiocy) that
NULL <> NULL- yes, everyNULLis unique.The reason that this is a problem is that if you want to have a column which is unique, without soft deletes you simply crate a unique index on that column. But when you add soft deletes, you now need to allow duplicates on this column, but with unique
deleted_atvalues - and unfortunately because of thisNULLissue, this means that the uniqueness is now not enforced for non-soft-deleted values. In essence, the choice ofdeleted_atusing aNULLto indicate a non-deleted record has been proven with hindsight to have been a poor choice, and use of e.g. the epoch timestamp of1970-01-01 00:00:01might have been a better choice.However, I wrote a package to fix this which is on Packagist as tranzakt/laravel-softdeletesunique that provides a solution for this.
EDIT note: See below for discussion on point 1. above. Upon reflection, I am no longer of the view that you need an index to support the
WHERE deleted_at IS NULLclause - so thanks to @David_Lunn for pointing this out. However point 2. is definitely a gotcha waiting to getcha.as first point is not valid, second loses it's purpose.
This is a reasonably well documented issue. Research it.
Thanks for clarification, yes it does index it. And did some research. Here's what i found:
Source: https://www.pepperoni.blog/sql-bit-and-index/
I think without in-depth performance testing with very specific data sets this topic is debatable and solution may be not applicable for everyone. And this is without taking into consideration different RDBs and engines.
As I explained in my original comment, the issue with use of
NULLin an index comes when you want it to be aUNIQUE INDEX. In a unique index,(NULL, "Surname1")is (as you would expect) different from(NULL, "Surname2")and(2023-12-31, "Surname1")but unexpectedly it is also different from(NULL, "Surname1")because everyNULLvalue is unique and different to every otherNULLvalue.This means that if you rely on a Unique Index to prevent duplicate records, then it will not prevent duplicates when you have a
NULLvalue in any field - and if you are going to prevent duplicates by coding (including ensuring that parallel transactions don't end-up creating duplicates) then you don't need a Unique Index at all.If you don't want to use a Unique Index, then I would agree that you would be better off not indexing the (very common) NULL value, but rather you should use the existing index (ignoring
deleted_at) and let the RDBMS filter out any soft deleted records from the small result-set.I know just how easy it is to validate uniqueness of request data before it is saved however I am not sure quite how easy it is to write application code to prevent creation of duplicate records by multiple parallel transactions i.e. the uniqueness checks happen first in parallel and then the inserts happen in parallel, but I would normally expect to do request validation but then still use Unique Indexes to ensure that the rare case of duplicates being created in parallel is also prevented.
Thinking about when the RDBMS does a full table scan rather than use an index, I am not sure that the decision is as simple as you say. For example, if the table has a short main row length (i.e. excluding e.g. large TEXT or JSON fields that the RDBMS stores elsewhere) then a full-scan may involve less I/O, whereas with a long row length (and especially if you only need the small subset of the columns that are in the index) then an index scan may be faster, and the choice will depend upon both the data and the sophistication of the optimiser.
That said, upon reflection the choice of whether to index e.g.
(surname, deleted_at)or(deleted_at, surname)will depend upon whether you only ever do e.g.SELECT id WHERE deleted_at IS NULL AND surname = 'Smith')in which case it is better to use(surname, deleted_at)(or(surname)) or whether you often doSELECT ... WHERE deleted_at IS NULL)(without the other index field) in which case you are probably better off using(NULL, surname). I would guess that some decent benchmarking would be needed for each RDBMS and maybe each version in order to determine the best strategy.Thanks for explanation, I appreciate.
It is really not difficult to handle that on application level without digging deep into rdb intricacies.
Basic idea of implementation might be something like this or abstracted in services.
Thanks for the code sample, however it will only work if the transaction fails, and the transaction will only fail if the database throws an error and that will only happen if a Unique Index constraint is triggered.
(Are you sure that a DB transaction wrapper is needed for a single database action of
Record::create()?)please note that
$request->validate(Record::$rules);checks if value already exists in db before transaction even begins, it is possible to define more complex closures to validate against different constraints with multiple columns or even relationships and conditionals including business logic, which otherwise would be difficult to do on db level.This is just an example to depict action, not specific case scenario.
My point is that (whilst unlikely), between validating the request (which includes a uniqueness check) and doing the commit, it is possible that another user running the same code at the same time has committed another record with the same unique value(s). So for this user, the validation succeeds, but by the time this user tries to commit the record, another record with the same unique values has already been added to the database.
If there is a database unique index for this, then the 2nd insert will fail, but if there isn't a unique index the insert will succeed leading to duplicate records in the database, and the exception is probably never going to be triggered (so why bother coding it).
That said, upon consideration, I guess it would be possible to code something so that after you have committed the record, then you check the database again, this time that there is exactly one value that should be unique, and if there are more than one then you delete the record you just created and raise an exception. But this is a lot more coding effort (and an additional database call and additional elapsed time) than having a unique index to disallow duplicate inserts.
(And in case you are thinking that this is so unlikely as never to happen, about 23 years ago I had to diagnose a system (written by a bunch of incompetents) that assumed that this would never happen, but it did on a regular basis. Ok - not a unique value issue, but definitely a multiple simultaneous update issue. There were several other issues - like not allowing more than 32767 records due to use of a 16-bit integer to hold the id - it was not well written. For the replacement application I designed some clever fuzzy search algorithms and the users loved it - but a few years after I left they replaced it again without these algorithms and the users went back to being unhappy. This must be the "Circle of Life" that they sang about in The Lion King.)
P.S. To show just how ancient I am, I first started playing with SQL databases in c. 1981 when I worked at IBM (SQL/R - the first ever SQL database based on research by IBM employees Codd & Date), and have been using them off and on ever since.
While I understand where you're coming from, it seems that you're trying to solve a problem you created itself as it ultimately diminishes your ability to restore records if another not deleted unique record exists in your table. That beats the purpose of having soft deletes at all. What if you try to delete that record again while the previous unique value is still soft-deleted?
It would be best to handle that complex logic on the application level (including exceptions and SQL errors) OR choose a different database design for your problem, as soft-deletes are not designed to use with unique values.
Maybe in this scenario moving "archived" entries into separate table during transaction might be better option overall so as a bonus we can avoid debate on full table scans vs index scans too.
Sorry, I don't buy the whole it is UNIQUE entry, but really IT IS NOT with these conditions <insert 99 parameters here> idea. What you're trying to solve is conditionally limiting the number of entries in the table. So it just happens that you used UNIQUE as a tool, and this is expected given your experience, and I respect that.
Not at all. The idea of a unique constraint is to ensure that you don't get two records with identical values in your database.
If you create a record with unique value ("NAME", NULL) then you shouldn't be able to create a second record with the same ("NAME", NULL). You then soft-delete that record changing it to ("NAME", date1). You can then create a new record ("NAME", NULL). And soft-delete that ("NAME", date2). You could then undelete ("NAME", date1) making it ("NAME", NULL) again, but you should NOT be allowed to then also undelete ("NAME", date2) because a unique non-deleted value now exists.
This is the purpose of this package. To ensure the correct uniqueness at the database level (rather than in the application).
What you're describing is a business logic how SQL would react if you used unique indices.
Speaking about business logic there could be cases where you might want to change that and is not applicable for every case, and could be wrapped in a transaction on application level with conditional checks (not only limited to uniqueness) as it prevents race conditions.
I'm not saying you can't do that the way you want and appreciate pointing out issues when using unique indices along SoftDeletes trait.
Let's move on with our lives.
The SoftDeletes trait simply creates additional functionality when you delete or restore a field.
The uniqueness is defined when you create the database fields for this package in the Migration.
That said, I am completely open to someone pointing out to me if I have got it wrong - I am as fallible as the next human.
Hello Povilas Korop, I'm using softdeletes on one of my models, but when I'm deleting softly one entry from the table I can't see it againg on the trashed tab and also it's excluded in the all tab. I don't know why the (where deleted_at is null) is included in the query, even I'm removing the softDeleteScope. I also noticed that when I'm using trashedFilter the problem gone. Can you help me and give me some advices? I also don't know why this was working before and this issue is appearing now. I tried tons of solutions but the problem still there. Thank you in advance.